-
 When using Postman, or other API clients (Thunder Client), you can download all the API commands and help associated to them. Although the NSX collections are still using OpenAPI Spec v2, while Thunder Client only supports OpenAPI Spec v3+.
When using Postman, or other API clients (Thunder Client), you can download all the API commands and help associated to them. Although the NSX collections are still using OpenAPI Spec v2, while Thunder Client only supports OpenAPI Spec v3+.
Read More -

When creating a new virtual service (VS) using NSX ALB (Avi) 22.1.1 & 22.1.1-2p1 in vCenter write access mode, it's supposed to create new Service Engines (SE's) if needed, but in the case today, it just sat there.
Hovering over the red VS status showed "Maximum failed attempts to create Service Engine …
Read More -
 Uh oh. You don't know the NSX ALB admin password, but if you have have another local account with Super User access, you can reset the admin password.
Uh oh. You don't know the NSX ALB admin password, but if you have have another local account with Super User access, you can reset the admin password.
Read More -

When browsing to the NSX-T Manager (3.1.3.x) interface, I see:
1Some appliance components are not functioning properly. 2Component health: MANAGER:UNKNOWN, SEARCH:UP, POLICY:UP, UI:UP, NODE_MGMT:UP. 3Error code: 101
Read More -

vIDM is part of VMware Cloud Foundation (VCF), and you may have multiple instances depending on the number of VCF deployments. In cases where the vIDM policy for network ranges is complex / limited, I found it efficient to use the vIDM API to push the same network ranges to all vIDM appliances. The official vIDM docs …
Read More -
 NSX Advanced load balancer is simple enough to configure with a remote syslog server entry, but it's a bit more complicated using syslog-tls (SSL).
NSX Advanced load balancer is simple enough to configure with a remote syslog server entry, but it's a bit more complicated using syslog-tls (SSL).
Read More -
 Replacing self-signed certificates on appliances is a lot easier these days. This is to remind myself how I did it for NSX Advanced Load Balancer using Let's Encrypt with DNS validation.
Replacing self-signed certificates on appliances is a lot easier these days. This is to remind myself how I did it for NSX Advanced Load Balancer using Let's Encrypt with DNS validation.
Read More -
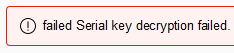
Applying a license to VMware NSX Advanced Load Balancer (Avi) version 21.1.3+ you may get an error:
failed Serial key decrytion failed. Failed to process serial key. SYSERR_LICENSE_DECRYPTION_FAILED Vmw error: NONE_FOUND
Read More